포트폴리오 사이트를 만들기로 했을 때 가장 먼저 한 질문은 이 사이트가 나를 어떻게 소개해야 하는가 였습니다.
단순히 프로젝트 목록을 나열하거나, 인터랙션 하나로 시선을 끄는 것만으로는 부족하다고 생각했습니다. 첫 인상부터 실제 콘텐츠 탐색, 이력서 다운로드, 방문자와의 교류까지 — 하나의 흐름으로 연결된 경험을 만들고 싶었습니다.
그래서 Chaen은 포트폴리오이면서 동시에 블로그, 프로젝트 아카이브, 이력서 배포 페이지, 방명록, 관리자 에디터를 하나의 제품으로 통합한 풀스택 프로젝트입니다.

3D 히어로 씬 — 입구 설계로서의 인터랙션
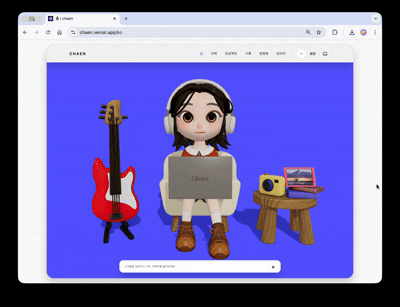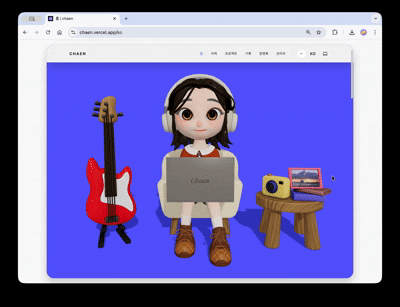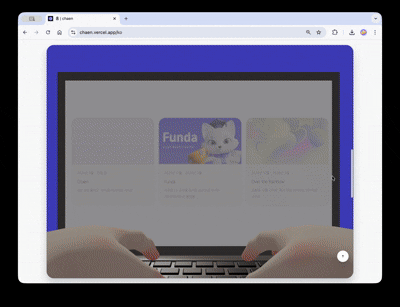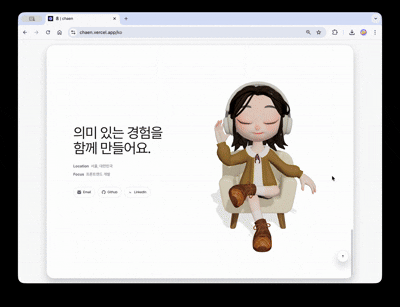
포트폴리오 사이트의 첫 화면의 목표는 3D 장면이 실제 웹 콘텐츠로 자연스럽게 이어지는 것이었습니다.
히어로 씬에는 캐릭터가 등장합니다. 일정 주기로 타이핑 · 알림 반응 애니메이션이 실행되고, 화면 좌측 기타를 클릭하면 줄별로 다른 소리가 나며 루프 트랙이 재생됩니다. 우측 카메라를 클릭하면 이미지 뷰어가 열리고, 선택한 이미지가 장면 속 액자 텍스처로 교체됩니다. 각 인터랙션은 서로 독립된 trigger–response 구조로 설계해, 3D 씬이 단순 배경이 아닌 조작 가능한 인터페이스로 작동합니다.
스크롤을 내리면 카메라가 180도 회전하면서 캐릭터의 노트북 화면으로 시점이 전환됩니다. 노트북이 점점 확대되면서 그 화면이 실제 HTML 오버레이로 교체되고, 클릭 가능한 프로젝트 쇼케이스로 이어집니다.
plaintext
연출의 자연스러움보다 전환 타이밍에서의 인터랙션 정합성이 더 중요했습니다. 3D 씬이 페이드아웃되는 도중에 HTML UI가 클릭되면 안 되기 때문에, Web UI 레이어의 pointer-events를 opacity 임계값과 함께 제어해 전환 중인 구간에서 잘못된 상호작용이 일어나지 않도록 처리했습니다.
R3F를 선택한 이유
3D 렌더링 라이브러리로 순수 Three.js 대신 React Three Fiber(R3F) 를 선택했습니다.
이 프로젝트는 Next.js + React 기반으로 구성되어 있는데, 순수 Three.js는 Scene, Camera, Renderer 초기화부터 애니메이션 루프, 리사이즈 핸들링까지 모든 설정을 직접 관리해야 합니다. R3F는 이 보일러플레이트를 React 컴포넌트 모델로 추상화해 카메라·조명·오브젝트를 JSX로 선언하고, Canvas 외부의 React 상태와 3D 씬 간 동기화도 자연스럽게 처리할 수 있습니다. 이 프로젝트처럼 스크롤 진행도·UI 레이어 상태·3D 씬이 긴밀하게 연결되는 구조에서 특히 유효한 선택이었습니다.
3D 자산 파이프라인 — Blender에서 웹까지
Funda에서 3D 캐릭터를 처음 구현할 때, Rigified Bone 런타임 구조의 한계를 직접 겪었습니다. 그 경험을 통해 깨달은 것은 성능 문제는 런타임 단계가 아닌 에셋 설계 단계부터 접근해야 한다는 점이었습니다. Funda에서는 애니메이션 데이터를 Blender에서 사전 베이킹해 런타임 bone matrix 연산을 줄이는 역할 분리로 해결했지만, 텍스처 메모리 · Draw Call · 버텍스 수 같은 지오메트리·렌더 파이프라인 레벨의 최적화는 별도로 풀어야 할 문제였습니다.
Chaen의 3D 자산은 이 관점에서 처음부터 설계했습니다. 런타임(R3F/Three.js)은 인터랙션만 담당하고, 비용은 Blender 단계에서 미리 줄입니다.
다이어그램을 렌더링하는 중입니다...
버텍스 최적화 — Subdivision Apply 없이 하이폴리 품질 확보
문제: 메시를 부드럽게 만드는 직관적인 방법은 Subdivision Surface를 Apply하는 것입니다. 하지만 Apply는 면의 개수를 단계마다 4배씩 증가시켜 웹 환경에서 직접적인 렌더링 비용이 됩니다.
해결: Subdivision Apply 없이 Weighted Normal 모디파이어로 노멀(법선) 방향만 재계산했습니다. 면의 개수는 그대로지만, 조명 계산에 사용되는 노멀이 하이폴리처럼 부드럽게 보간됩니다. 메시 구조에 따라 특정 엣지에서 노멀 방향이 어긋나는 현상이 발생하는데, 면 단위 노멀 가중치를 직접 조율해 깨짐 없이 원하는 품질을 확보했습니다.
텍스처 아틀라스 — Draw Call 최소화
문제: Three.js에서 머티리얼이 다른 오브젝트는 한 번에 그리지 못합니다. 파츠마다 별도 머티리얼을 사용하면 Draw Call이 파츠 수만큼 발생합니다.
해결: 관련 파츠를 용도별로 묶어 UV를 아틀라스 좌표에 맞게 재배치하고, 하나의 아틀라스 텍스처로 통합해 머티리얼 참조를 공유하도록 변경했습니다. 같은 머티리얼을 공유하는 오브젝트는 하나의 Draw Call로 묶입니다.
ORM 패킹 — 텍스처 3장을 1장으로
문제: PBR 워크플로우에서 Occlusion, Roughness, Metalness는 각각 별도 텍스처가 필요합니다. 텍스처 3장은 3배의 GPU 메모리와 네트워크 전송량을 의미합니다.
해결: 세 채널 모두 그레이스케일 데이터(0–1 스칼라값)이므로, 하나의 이미지 R · G · B 채널에 각각 패킹했습니다. 텍스처 3장 → 1장으로 절감되어 GPU 메모리와 초기 로딩 전송량이 동시에 줄어듭니다.
인스턴싱 — 동일 지오메트리 중복 연산 제거
같은 지오메트리가 여러 곳에 쓰이는 경우 인스턴싱 기법으로 GPU에 한 번만 올려 중복 연산을 제거했습니다.
반응형 씬 모드
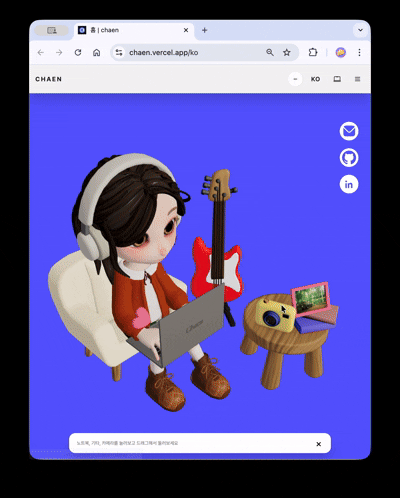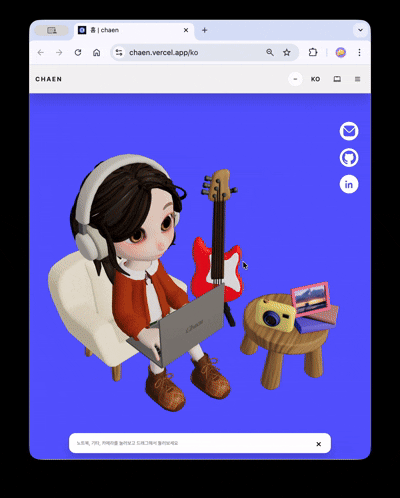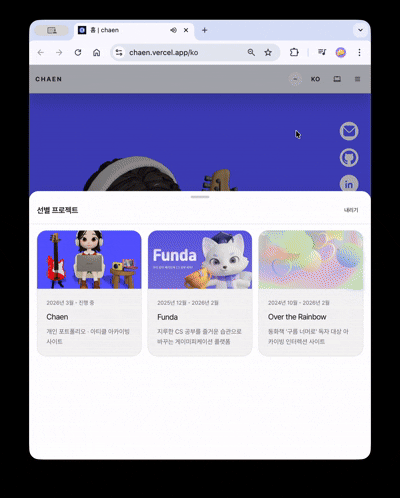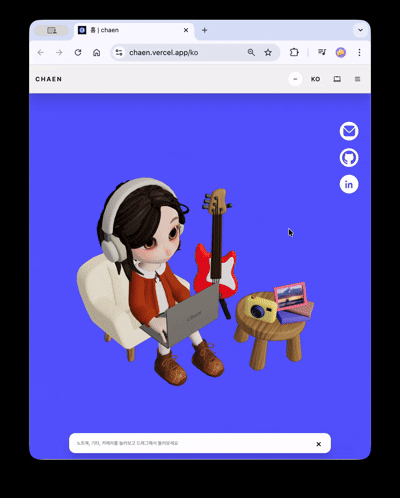
3D 씬은 viewport aspect ratio를 기반으로 stacked(세로 비율 우세) / wide(가로 비율 우세) 두 모드로 분기됩니다.
- stacked: 탭 · 드래그 중심 인터랙션. contact 씬과 같은 보수적 DPR 상한 설정으로 렌더 비용을 낮춥니다.
- wide: 스크롤 기반 카메라 전환 경험 유지. 필요한 품질만 남깁니다.
중간 예외 상태 없이 두 모드 중 하나로만 분기되도록 규칙을 단순화했습니다. prefers-reduced-motion 사용자에게는 강한 카메라 이동을 생략해 짧고 단정한 진입 경험을 제공하고, WebGL 미지원 환경에는 3D 없이 안전한 fallback을 보여줍니다.
다국어와 SEO — 보이지 않는 곳까지
Chaen은 ko / en / ja / fr 4개 언어를 지원합니다. 다국어 사이트에서 중요한 건 번역 문자열이 여러 개 있다는 사실보다, 번역 누락이나 경로 분기 때문에 사용자 경험과 검색 노출이 동시에 깨지지 않는 구조입니다.
콘텐츠 데이터 모델
콘텐츠는 구조로 설계했습니다. , , 는 공통 slug를 기준 식별자로 유지하고, 실제 제목과 본문은 같은 별도 테이블에서 locale별로 관리합니다. 요청이 들어오면 target locale → → → → 순서로 가장 적절한 번역을 선택합니다.
URL과 콘텐츠 참조는 안정적으로 유지하면서, 화면에 보여줄 제목·설명·라벨만 translation pool에서 선택합니다.
번역 파이프라인 — n8n 자동화
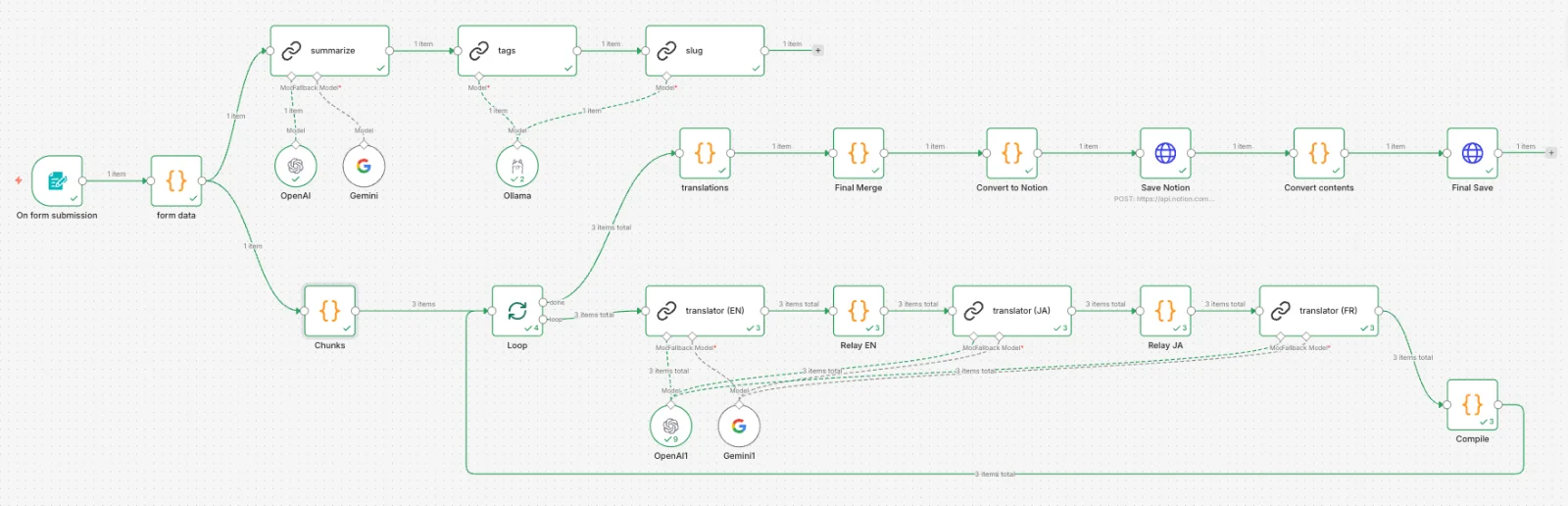
콘텐츠 데이터 모델이 article_translations로 분리되어 있어도, 번역 자체가 병목이 되면 다국어 지원은 유지하기 어려운 구조가 됩니다. 아티클 하나를 3개 언어로 번역·검토·저장하는 과정을 매번 수작업으로 하면 글 발행 자체가 부담이 됩니다.
이 문제를 해결하기 위해 n8n 기반 번역 자동화 파이프라인을 구성했습니다. 폼에 제목·설명·본문 Markdown을 입력하면 태그 추출, Slug 생성, EN/JA/FR 번역, Notion 저장까지 한 번에 처리됩니다.
plaintext
설계 결정 몇 가지:
요약 선행
- 전체 본문을 태그/Slug LLM에 직접 넣으면 요약 대신 본문을 그대로 반환하는 현상이 발생했습니다. 2~3문장 요약을 먼저 만들고 태그·Slug 생성에 참조하도록 분리했습니다.
역할별 모델 분리
번역·요약처럼 품질이 중요한 작업은 OpenAI, 태그·Slug처럼 짧은 구조화 출력이 목적인 작업은 로컬 Ollama로 분리했습니다. API 비용을 줄이면서 품질은 유지합니다.
청크 단위 번역
긴 아티클을 통째로 번역 요청하면 중간 내용이 누락되거나 Markdown 구조가 깨지는 경우가 있었습니다. H2 헤딩 기준으로 청크를 나누고 순차 처리합니다. 각 청크 번역 결과는 중계 노드에서 누적해 다음 언어로 전달하고, 루프 완료 후 전체를 병합합니다.
구조화 출력
번역 결과를 { title, description, content } JSON으로 받아 Notion 프로퍼티(메타)와 페이지 본문(블록)을 분리 저장합니다. Notion API의 100블록 제한에 맞춰 본문은 배치 단위로 나눠 PATCH 요청합니다.
보이지 않는 locale 자산
화면에 보이는 텍스트뿐 아니라 aria-label, placeholder, 오류 메시지, 스크린 리더용 상태 텍스트까지 전부 locale 자산으로 관리했습니다. 본문만 번역되고 안내 문구가 다른 언어로 남아 있으면 경험은 금방 조각납니다. 사용자가 "보는 언어"와 보조기기가 "읽는 언어"가 분리되지 않도록 한 것입니다.
SEO 인프라
canonical · hreflang 자동화
각 페이지의 generateMetadata 단계에서 locale별 canonical과 hreflang alternate를 자동 계산하도록 구성했습니다. 번역 누락이 생기면 fallback locale을 canonical로 가리켜 duplicate content 가능성을 줄이면서도 사용자에게는 fallback 콘텐츠를 계속 제공합니다.
JSON-LD 구조화 데이터
아티클 상세에는 BlogPosting, 프로젝트 상세에는 CreativeWork, 공통 breadcrumb에는 BreadcrumbList 스키마를 주입했습니다. 검색엔진이 HTML 파싱 외의 방식으로도 문서 타입·제목·게시 시점·페이지 계층을 명확하게 해석할 수 있도록 했습니다.
동적 sitemap / robots
정적 XML 파일 대신 Next.js Metadata API 기반으로 sitemap과 robots를 코드에서 생성합니다. Supabase 데이터와 실제 URL 구조를 바로 반영하고, locale가 늘거나 데이터가 바뀌어도 sitemap이 자동으로 최신 상태를 유지합니다. 관리자·콜백·게스트북 경로는 noindex, nofollow로 명시적으로 차단했습니다.
상세 페이지 진입 속도 개선 — 5초 → 1초 이내
목록에서 아티클 상세로 이동할 때 체감 대기 시간이 약 5초에 달하는 경우가 있었습니다. 좌측 아카이브 목록, 태그 라벨, 관련 글, 다국어 locale fallback 처리가 모두 같은 우선순위로 준비될 때까지 사용자가 기다리는 구조가 문제였습니다. 개별 fetch가 느린 게 아니라, 직렬로 묶인 레이어들이 전부 완료되기 전까지 아무것도 보이지 않았습니다.
본문 우선 스트리밍 — 렌더 타이밍 분리
본문 shell에 꼭 필요한 데이터와 나중에 와도 되는 보조 데이터를 분리했습니다. 아카이브 목록, 태그, 관련 글은 await 없이 Promise만 시작한 뒤 section-level Suspense fallback으로 전달합니다. 본문이 먼저 보이고, 보조 섹션은 Skeleton을 거쳐 후행 로딩됩니다.
다이어그램을 렌더링하는 중입니다...
캐시 구조 단일화
page 레벨 ISR(revalidate = 3600)과 entity 단 unstable_cache가 중첩되어 stale 원인 파악이 복잡했습니다. page ISR을 제거하고 entity cache + write 이후 명시적 무효화만 남겼습니다. 캐시 계층이 하나가 되면서 stale 원인을 한 곳에서만 추적하면 됩니다.
캐시 히트 여부는 서버 로그로 직접 측정합니다. unstable_cache 함수 본문은 cache miss 시에만 실행되므로, 내부에 [cache-miss:article] 로그를 심으면 DB 쿼리 발생 여부를 알 수 있습니다.
plaintext
[cache-miss:article] slug="fe-performance" locale="ko" ← cache miss 시에만 출력
[perf:article] slug="fe-performance" locale="ko" ms=4 ← 항상 출력 (hit: <5ms)
[perf:article] slug="fe-performance" locale="ko" ms=340 ← miss 시 쿼리 비용 노출댓글과 본문의 캐시 책임 분리
댓글은 본문과 완전히 다른 freshness 요구사항을 가집니다. 댓글만 브라우저 세션 범위 메모리 캐시(TTL 60초)로 분리해 본문 진입을 막지 않도록 했습니다. 댓글 작성·수정·삭제 직후에는 해당 아티클의 모든 캐시 엔트리를 즉시 삭제해 stale 데이터가 재사용되지 않습니다.
무한 스크롤 요청 구조 개선
무한 스크롤 "다음 페이지 조회"가 POST 기반 Server Action을 사용하고 있었습니다. 순수 read 요청이 mutation transport를 타는 구조였습니다. GET /api/articles?cursor=... Route Handler로 전환하고 Cache-Control: s-maxage=60, stale-while-revalidate=300을 추가했습니다. 실제 데이터 freshness는 entity 캐시가 결정하고, transport는 read 자원처럼 동작합니다.
결과
체감 속도는 약 5초에서 0.5~1초 수준으로 줄었습니다. 수치보다 더 달라진 건, "주변이 늦게 붙는 느낌"이 사라지고 본문이 먼저 안정적으로 보인다는 점이었습니다.
이 구조가 단계적으로 정리될 수 있었던 것은 route · view · entity · feature의 책임이 FSD 관점으로 나뉘어 있었기 때문입니다. 병목을 만드는 레이어를 하나씩 분리하며 진행할 수 있었습니다.
4. Offset → Keyset 커서 페이지네이션과 탐색 UX
콘텐츠가 늘어날수록 목록 탐색은 단순한 리스트 렌더링 문제가 아니라 정보 구조 문제가 됩니다. 기존 Offset 방식은 두 가지 문제를 안고 있었습니다. 페이지가 뒤로 갈수록 DB가 앞의 데이터를 모두 읽고 버려야 하는 O(N) 성능 저하, 그리고 사용자가 스크롤하는 도중 새 글이 올라오면 피드가 튀는 중복 노출입니다.
커서 구조 설계
publish_at + id 조합을 불투명(Opaque) 커서로 직렬화해 절대 좌표 기반 페이지네이션을 구현했습니다. "특정 시점 이전"이라는 고정된 기준으로 조회하기 때문에 실시간으로 글이 업데이트되어도 피드 흐름이 끊기지 않고, 인덱스를 타고 필요한 데이터만 조회하므로 데이터 규모와 무관하게 O(log N) 성능을 유지합니다.
다이어그램을 렌더링하는 중입니다...
검색에 Keyset 확장 — PostgreSQL FTS + rank 커서
검색 결과에도 같은 커서 구조를 확장했습니다. 검색어가 있을 때는 연관도(rank) + publish_at + id 3단계 정렬 좌표를 커서로 직렬화해, 관련도순 정렬을 유지하면서도 페이지 경계에서 중복/누락이 발생하지 않도록 했습니다.
검색 성능은 tsvector 컬럼을 DB 트리거로 사전 계산해 GIN 인덱스를 타도록 구성했습니다. 검색 요청마다 CPU를 쓰는 대신, 데이터 생성/수정 시 미리 지문을 만들어 두는 방식입니다. 제목(가중치 A)과 설명(가중치 B)에 차등 점수를 부여해 검색 정확도도 함께 개선했습니다.
다이어그램을 렌더링하는 중입니다...
SEO와 탐색 UX 연결
커서 기반 URL은 상태값을 포함하기 때문에 그대로 두면 검색 색인에 부정적인 영향을 줍니다. noindex, follow와 Canonical 태그를 커서 URL에 적용해 크롤러가 중복 색인하지 않도록 했고, 동시에 rel="prev" / rel="next" 메타데이터를 생성해 봇은 정적인 페이지 링크를 따라갈 수 있는 구조를 유지했습니다.
비정상 deep-link 처리
keyset은 page 번호만으로 목표 위치를 복원할 수 없습니다. ?page=N 형태의 수동 deep-link는 cursor 없이 진입하는 경우 notFound()로 처리해 서버가 중간 페이지를 직렬 복원하는 비용을 없앴습니다.
상세 아카이브 보정
상세 페이지 좌측 아카이브는 현재 보고 있는 항목을 목록에 끼워 넣어 사용자가 목록 맥락을 잃지 않도록 했습니다. 이때 nextCursor도 실제 마지막 렌더링 아이템 기준으로 다시 계산해 다음 페이지가 누락 없이 이어지도록 처리했습니다.
자동 로드 gate
sentinel이 초기에 뷰포트에 보인다는 이유만으로 의도하지 않은 추가 요청이 발생하지 않도록, 사용자가 실제로 스크롤 의도를 보인 이후에만 자동 로드가 동작하도록 처리했습니다.
다이어그램을 렌더링하는 중입니다...
5. 접근성과 인터랙션 품질
인터랙션이 많은 사이트일수록 접근성 품질은 작은 실수의 누적으로 무너집니다. 접근성을 마감 체크리스트가 아닌 인터랙션 설계와 함께 올라가는 품질 기준으로 다뤘습니다.
모달·팝오버 Focus Trap
진입 시 첫 포커스 요소로 이동, Tab 순환, Escape 시 닫기, 닫힐 때 이전 포커스 복귀까지 처리하는 공용 훅을 만들었습니다. 컴포넌트 하나하나를 개별 대응하는 대신 공용 레이어에 모아, 인터랙션이 늘어나도 포커스 흐름이 일관되게 유지되도록 했습니다.
상태 전달
검색 폼에는 , , 상태 텍스트를 적용해 시각적으로 보이지 않는 진행 상태까지 전달했습니다. 스포일러, 태그 필터, 페이지네이션, 액션 메뉴에도 , , focus-visible 스타일을 일관되게 적용했습니다.
아이콘과 locale 자산
아이콘이 장식용인지 의미 전달용인지에 따라 과 을 구분해 처리하는 공용 아이콘 래퍼를 만들었습니다. , , 에 연결되는 스크린 리더용 문구, keyboard shortcut 힌트, input validation message까지 전부 locale 단위로 관리했습니다. 사용자가 "보는 언어"와 보조기기가 "읽는 언어"가 분리되지 않도록 한 것입니다.
마치며
Chaen은 개인 포트폴리오를 넘어, 제가 어떤 기준으로 프론트엔드 제품을 설계하는지를 보여주는 프로젝트입니다.
인터랙션을 좋아하지만, 인터랙션 자체만으로 프로젝트를 설명하고 싶지는 않습니다. 좋은 인터랙션은 성능, 접근성, 정보 구조, 검색 친화성, 운영성까지 함께 설계될 때 비로소 제품 경험이 됩니다. Chaen은 그 관점을 가장 집약적으로 담은 작업입니다.