ポートフォリオサイトを作ることに決めたとき、最初にした質問はこのサイトが私をどのように紹介すべきかでした。
単にプロジェクトの一覧を並べたり、インタラクションで目を引くだけでは不十分だと思いました。第一印象から実際のコンテンツ探索、履歴書のダウンロード、訪問者との交流まで、一つの流れで繋がった体験を作りたかったのです。
そのため、Chaenはポートフォリオでありながら同時にブログ、プロジェクトアーカイブ、履歴書配布ページ、ゲストブック、管理者エディターを一つの製品として統合したフルスタックプロジェクトです。

3Dヒーローシーン — エントランスデザインとしてのインタラクション
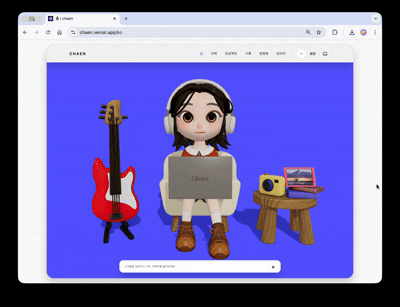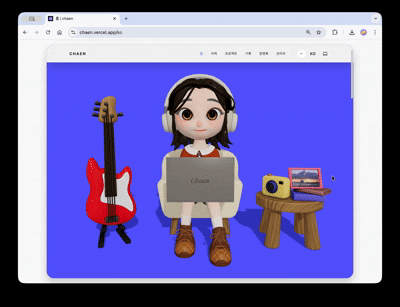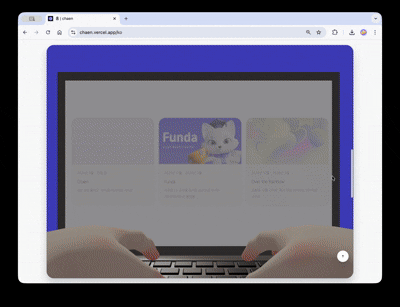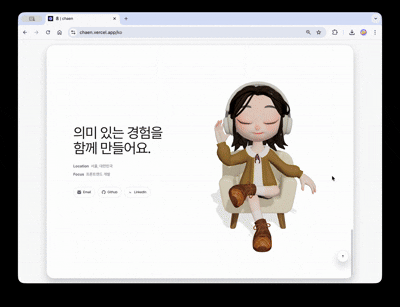
ポートフォリオサイトの最初の画面の目標は、3Dシーンが現実のウェブコンテンツへ自然に繋がることでした。
ヒーローシーンにはキャラクターが登場します。一定周期でタイピング・通知反応アニメーションが実行され、画面左側のギターをクリックすると、弦ごとに異なる音が出てループトラックが再生されます。右側のカメラをクリックすると、イメージビューアーが開き、選択した画像がシーン内の額縁テクスチャに置き換わります。各インタラクションは独立したトリガー・レスポンス構造で設計され、3Dシーンが単なる背景ではなく、操作可能なインターフェースとして機能します。
スクロールするとカメラが180度回転し、キャラクターのノートパソコン画面へ視点が切り替わります。ノートパソコンがだんだんと拡大し、その画面が実際のHTMLオーバーレイに置き換わり、クリック可能なプロジェクトショーケースへと続きます。
plaintext
演出の自然さよりも、転換タイミングでのインタラクション整合性が重要でした。3Dシーンがフェードアウト中にHTML UIがクリックされることがないように、Web UIレイヤーのpointer-eventsを不透明度の閾値と共に制御し、転換中の区間での誤った相互作用が起こらないように処理しました。
R3Fを選んだ理由
3Dレンダリングライブラリとして純粋なThree.jsの代わりにReact Three Fiber(R3F) を選びました。
このプロジェクトはNext.js+Reactベースで構成されており、純粋なThree.jsはScene、Camera、Rendererの初期化からアニメーションループ、リサイズ処理まで全ての設定を自行管理する必要があります。R3FはこのボイラープレートをReactコンポーネントモデルに抽象化し、カメラ・照明・オブジェクトをJSXで宣言し、Canvas外部のReact状態と3Dシーン間の同期も自然に処理できます。このプロジェクトのようにスクロール進行度・UIレイヤー状態・3Dシーンが緊密に連結される構造では特に有効な選択でした。
3Dアセットパイプライン — Blenderからウェブまで
Fundaで3Dキャラクターを初めて実装する際、Rigified Boneランタイム構造の限界を直接体験しました。その経験を通じてわかったのは、性能問題はランタイム段階ではなく、アセット設計段階からアプローチすべきだという点でした。FundaではアニメーションデータをBlenderで事前ベーキングしてランタイムbone matrix演算を減らす役割分離で解決しましたが、テクスチャメモリ・Draw Call・バーテックス数といったジオメトリ・レンダーパイプラインレベルの最適化は別途解決すべき問題でした。
Chaenの3Dアセットはこの観点から最初から設計しました。ランタイム(R3F/Three.js)はインタラクションのみを担当し、コストはBlender段階で事前に削減しています。
다이어그램을 렌더링하는 중입니다...
バーテックス最適化 — Subdivision Applyなしでハイポリ品質確保
問題: メッシュを滑らかにする直感的な方法はSubdivision SurfaceをApplyすることです。しかし、Applyは面の数を段階ごとに4倍ずつ増やし、ウェブ環境で直接的なレンダリングコストになります。
解決: Subdivision ApplyなしでWeighted Normalモディファイアでノーマル(法線)方向のみを再計算しました。面の数はそのままですが、照明計算に使用されるノーマルがハイポリのように滑らかに補間されます。メッシュ構造により特定エッジでノーマル方向がずれる現象が発生しますが、面単位のノーマル重みを直接調整して破損なく望む品質を確保しました。
テクスチャアトラス — Draw Call最小化
問題: Three.jsでマテリアルが異なるオブジェクトは一度に描画できません。パーツごとに別のマテリアルを使用するとDraw Callがパーツ数分発生します。
解決: 関連パーツを用途別にまとめ、UVをアトラス座標に合わせて再配置し、1つのアトラステクスチャに統合してマテリアル参照を共有するように変更しました。同じマテリアルを共有するオブジェクトは1つのDraw Callにまとめられます。
ORMパッキング — テクスチャ3枚を1枚に
問題: PBRワークフローでOcclusion、Roughness、Metalnessはそれぞれ別のテクスチャが必要です。テクスチャ3枚は3倍のGPUメモリとネットワーク転送量を意味します。
解決: 3つのチャンネルは全てグレースケールデータ(0–1スカラー値)なので、1つのイメージR · G · Bチャンネルにそれぞれパッキングしました。テクスチャ3枚→1枚に節減され、GPUメモリと初期のロード転送量が同時に減ります。
インスタンシング — 同一ジオメトリ重複演算除去
同じジオメトリが複数箇所で使われる場合、インスタンシング手法でGPUに一度だけ載せて重複演算を除去しました。
反応型シーンモード
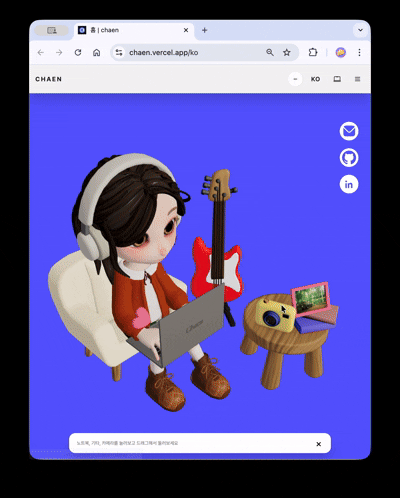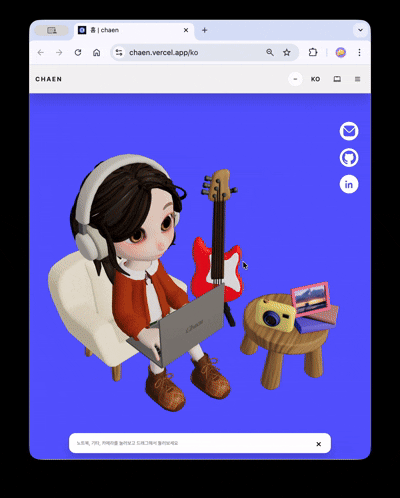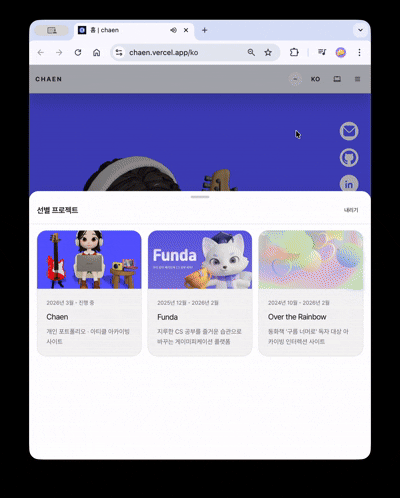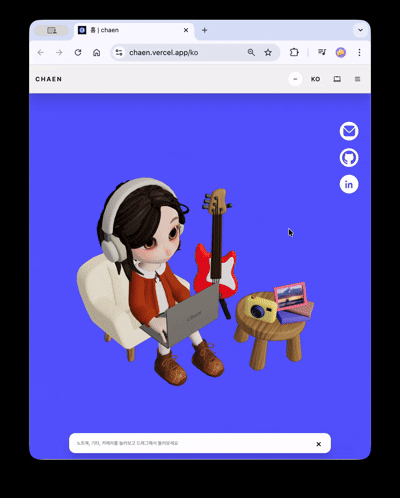
3Dシーンはビューポートアスペクト比に基づきstacked(縦比率優勢) / wide(横比率優勢)の2つのモードに分岐します。
- stacked: タップ・ドラッグ中心のインタラクション。contactシーンのような保守的DPR上限設定でレンダーコストを下げます。
- wide: スクロール基盤のカメラ転換体験を維持。必要な品質だけを残します。
中間例外状態なしに2つのモードのいずれかにのみ分岐するようルールを単純化しました。prefers-reduced-motionユーザーには強いカメラ移動を省略し、短く端正なエントリー体験を提供し、WebGL未対応環境には3Dなしで安全なフォールバックを表示します。
多言語とSEO — 見えないところまで
Chaenは「ko / en / ja / fr」の4つの言語をサポートします。多言語サイトで重要なのは、翻訳文字列が複数あることよりも、翻訳の漏れやルートの分岐によってユーザー体験と検索露出が同時に壊れることのない構造です。
コンテンツデータモデル
コンテンツはの構造で設計しました。、、は共通のスラグを基準に識別子を維持し、実際のタイトルと本文はなどの別テーブルでロケールごとに管理します。リクエストが来るとtarget locale → → → → の順で最も適切な翻訳を選びます。
URLとコンテンツの参照は安定的に維持しつつ、表示されるタイトル・説明・ラベルのみをtranslation poolから選びます。
翻訳パイプライン — n8n自動化
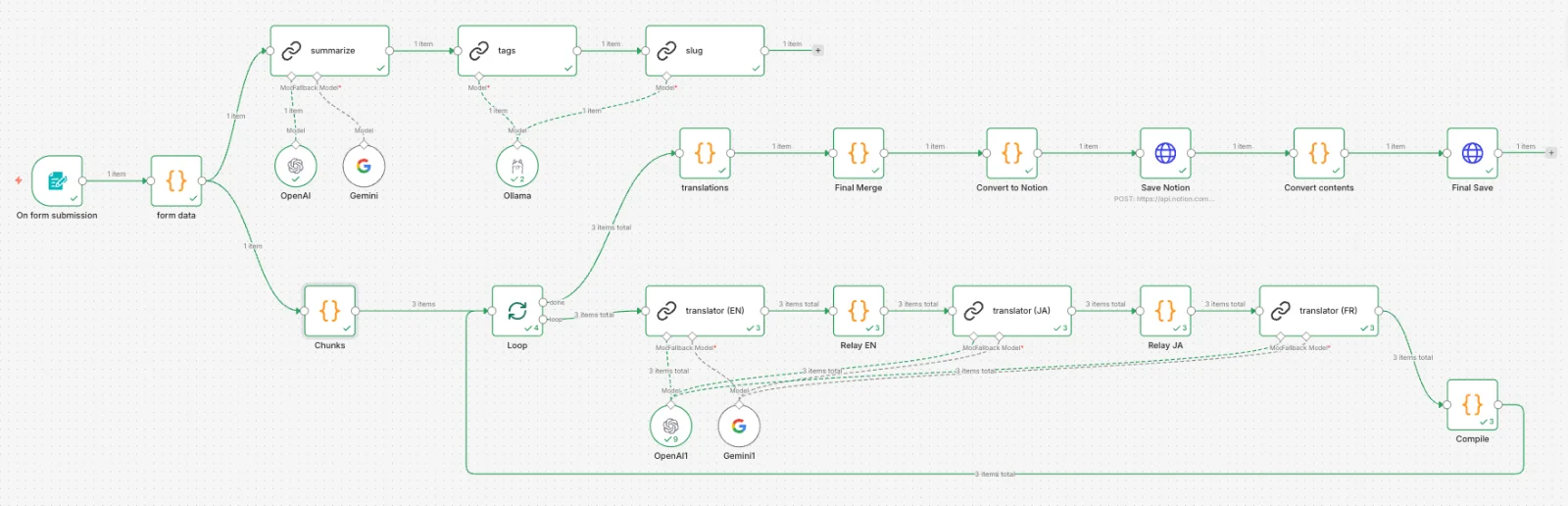
コンテンツデータモデルがarticle_translationsに分離されていても、翻訳そのものがボトルネックになると多言語対応は持続しにくい構造になります。記事一つを3つの言語に翻訳・検討・保存する過程を毎回手作業で行うと、記事の発行自体が負担となります。
この問題を解決するためにn8nベースの翻訳自動化パイプラインを構築しました。フォームにタイトル・説明・本文Markdownを入力するとタグ抽出、スラグ生成、EN/JA/FR翻訳、Notionへの保存まで一度に処理されます。
plaintext
設計の決定要素:
要約の先行
- 全体の本文をタグ/スラグLLMに直接入れると、要約の代わりに本文をそのまま返す現象が発生しました。2~3文の要約を先に作成し、タグ・スラグ生成に参照するように分離しました。
役割別モデル分離
翻訳・要約のように品質が重要な作業はOpenAI、タグ・スラグのように短い構造化出力が目的の作業はローカルOllamaで分離しました。APIコストを抑えながら品質を維持します。
チャンク単位翻訳
長い記事を丸ごと翻訳リクエストすると中間の内容が漏れたりMarkdown構造が崩れる場合がありました。H2見出しを基準にチャンクを分けて順次処理します。各チャンクの翻訳結果は中継ノードで積み重ね次の言語に伝達し、ループ完了後に全体を統合します。
構造化出力
翻訳結果を{ title, description, content }のJSONで受け取り、Notionプロパティ(メタ)とページ本文(ブロック)を分離保存します。Notion APIの100ブロック制限に合わせて本文はバッチ単位で分割してPATCHリクエストします。
見えないロケール資産
画面に見えるテキストだけでなく「aria-label」、プレースホルダー、エラーメッセージ、スクリーンリーダー用の状態テキストまで全てロケール資産として管理しました。本文のみ翻訳され案内文が他の言語で残ると体験はすぐに崩れます。ユーザーが「見る言語」と補助機器が「読む言語」が分離されないようにしました。
SEOインフラ
canonical · hreflang自動化
各ページのgenerateMetadata段階でロケール別のcanonicalとhreflang alternateを自動計算するように構成しました。翻訳漏れが生じた場合はfallback localeをcanonicalに指して重複コンテンツの可能性を減らしつつ、ユーザーにはfallbackコンテンツを提供し続けます。
JSON-LD構造化データ
記事の詳細には「BlogPosting」、プロジェクトの詳細には「CreativeWork」、共通のパン層リストには「BreadcrumbList」スキーマを挿入しました。検索エンジンがHTML解析以外の方法でも文章のタイプ・タイトル・掲載時点・ページ階層を明確に解釈できるようにしました。
動的サイトマップ / ロボット
静的XMLファイルの代わりにNext.js Metadata APIベースでサイトマップとロボットをコードから生成します。Supabaseデータと実際のURL構造を即反映し、ロケールが増えたりデータが変わってもサイトマップが自動的に最新の状態を保ちます。管理者・コールバック・ゲストブックパスは「noindex, nofollow」で明示的にブロックしました。
詳細ページの進入速度改善 — 5秒 → 1秒以内
リストから記事詳細に移動する時、体感待ち時間が約5秒に達することがありました。左側のアーカイブリスト、タグラベル、関連記事、多言語ロケールフォールバック処理が全て同じ優先順位で準備されるまでユーザーが待つ構造が問題でした。個別のフェッチが遅いのではなく、直列に結ばれたレイヤーが全て完了するまで何も表示されませんでした。
本文優先ストリーミング — レンダータイミング分離
本文シェルに必要なデータと後で来ても良い補助データを分離しました。アーカイブリスト、タグ、関連記事はawaitなしでPromiseだけを開始し、セクションレベルのSuspenseフォールバックで提供します。本文が先に表示され、補助セクションはスケルトンを経て後続ロードされます。
다이어그램을 렌더링하는 중입니다...
キャッシュ構造単一化
ページレベルISR(revalidate = 3600)とエンティティ単位のunstable_cacheが重なり、ステールの原因把握が複雑でした。ページISRを削除し、エンティティキャッシュ + 書き込み後の明示的無効化のみ残しました。キャッシュ階層が一つになり、ステールの原因を一ヶ所で追跡すればよくなります。
キャッシュヒットかどうかはサーバーログで直接測定します。unstable_cache 関数本文はキャッシュミス時のみ実行されるので、内部に[cache-miss:article]ログを埋め込むとDBクエリ発生有無がわかります。
plaintext
[cache-miss:article] slug="fe-performance" locale="ko" ← キャッシュミス時のみ出力
[perf:article] slug="fe-performance" locale="ko" ms=4 ← 常に出力 (ヒット: <5ms)
[perf:article] slug="fe-performance" locale="ko" ms=340 ← ミス時クエリコスト露出コメントと本文のキャッシュ責任分離
コメントは本文と全く異なる新鮮さ要件を持っています。コメントのみブラウザセッション範囲メモリキャッシュ(TTL 60秒)で分離し、本文進入を妨げないようにしました。コメントの作成・修正・削除直後には該当記事の全てのキャッシュエントリを即時削除し、ステールデータが再利用されないようにします。
無限スクロール要求構造改善
無限スクロール「次ページ照会」がPOSTベースのサーバーアクションを使用していました。純粋な読み取り要求がミューテーション送信を通る構造でした。GET /api/articles?cursor=... ルートハンドラに転換し、Cache-Control: s-maxage=60, stale-while-revalidate=300を追加しました。実データの新鮮さはエンティティキャッシュが決定し、送信は読み取り資源のように動作します。
結果
体感速度は約5秒から0.5~1秒のレベルに減りました。数値よりも変わったのは、「周辺が遅れて接続する感じ」が消え、本文が先に安定して見えるという点でした。
この構造が段階的に整理できたのは、ルート・ビュー・エンティティ・フィーチャーの責任がFSDの観点から分かれていたからです。ボトルネックを作るレイヤーを一つずつ分離し進行できました。
4. オフセット → キーセット・カーソル・ページネーションと探索UX
コンテンツが増えるにつれて、リスト探索は単なるリストレンダリングの問題ではなく、情報構造の問題となります。従来のオフセット方式には2つの問題がありました。ページが後ろに行くにつれて、DBが前のデータをすべて読み取って捨てなければならないO(N)の性能低下、およびユーザーがスクロール中に新しい投稿が上がるとフィードが跳ねる重複表示です。
カーソル構造設計
publish_at + id の組み合わせを不透明(オペーク)カーソルとして直列化し、絶対座標に基づくページネーションを実現しました。「特定時点以前」という固定された基準で照会するため、リアルタイムで投稿が更新されてもフィードの流れが途切れず、インデックスを辿って必要なデータのみを照会するため、データ規模に関係なくO(log N)の性能を維持します。
다이어그램을 렌더링하는 중입니다...
検索におけるキーセット拡張 — PostgreSQL FTS + ランクカーソル
検索結果にも同じカーソル構造を拡張しました。検索語がある場合は関連度(ランク) + publish_at + id の3段階の整列座標をカーソルとして直列化し、関連度順の整列を維持しつつ、ページ境界での重複や欠落が発生しないようにしました。
検索性能は tsvector カラムをDBトリガーで事前計算しGINインデックスを利用するように構成しました。検索リクエストごとにCPUを使う代わりに、データ生成/修正時に指紋を作っておく方式です。タイトル(重みA)と説明(重みB)に差等スコアを付与し、検索精度も一緒に改善しました。
다이어그램을 렌더링하는 중입니다...
SEOと探索UXの連携
カーソルベースのURLは状態値を含むため、そのままにしておくと検索インデックスに悪影響を与えます。noindex, follow と Canonical タグをカーソルURLに適用して、クローラーが重複インデックスしないようにし、同時に rel="prev" / rel="next" メタデータを生成してボットが静的なページリンクを辿れる構造を維持しました。
異常deep-link処理
キーセットはページ番号だけで目標位置を復元できません。?page=N 形式の手動deep-linkはカーソルなしで進入する場合 notFound() で処理してサーバーが中間ページを直列復元するコストをなくしました。
詳細アーカイブの補正
詳細ページの左側アーカイブは、現在表示している項目をリストに挿入してユーザーがリストのコンテキストを失わないようにしました。この際、nextCursor も実際の最後のレンダリングアイテム基準で再計算し、次のページが欠落なく続くように処理しました。
自動ロードゲート
センチネルが初期にビューポートに見えるという理由だけで意図しない追加リクエストが発生しないように、ユーザーが実際にスクロールの意図を示した後にのみ自動ロードが動作するように処理しました。
다이어그램을 렌더링하는 중입니다...
5. アクセシビリティとインタラクションの品質
インタラクションが多いサイトほど、アクセシビリティの品質は小さなミスの積み重ねで崩れてしまいます。アクセシビリティを最終チェックリストではなく、インタラクション設計と共に向上させる品質基準として扱いました。
モーダル・ポップオーバーのフォーカストラップ
進入時に最初のフォーカス要素に移動し、Tabで循環し、Escape時に閉じることや、閉じたときに以前のフォーカスに戻るまでを処理する共用フックを作成しました。コンポーネントを一つ一つ別々に対応する代わりに、共用レイヤーにまとめて、インタラクションが増えてもフォーカスの流れが一貫して維持されるようにしました。
状態伝達
検索フォームには、、の状態テキストを適用して視覚的に見えない進行状態まで伝えました。スポイラー、タグフィルター、ページネーション、アクションメニューにも、、focus-visibleスタイルを一貫して適用しました。
アイコンとlocaleアセット
アイコンが装飾用か意味伝達用かによってとを区分して処理する共用アイコンラッパーを作成しました。、、に接続されるスクリーンリーダー用の文句、キーボードショートカットのヒント、input validationメッセージまで全てをロケール単位で管理しました。ユーザーが「見る言語」と補助機器が「読む言語」が分離されないようにしたのです。
おわりに
Chaenは個人のポートフォリオを超えて、私がどのような基準でフロントエンド製品を設計しているかを示すプロジェクトです。
インタラクションが好きですが、インタラクション自体だけでプロジェクトを説明したくはありません。良いインタラクションは性能、アクセシビリティ、情報構造、検索フレンドリーさ、運用性まで一緒に設計されたときに初めて製品の体験となります。Chaenはその観点を最も集約的に込めた作業です。