Lorsque j'ai décidé de créer un site portfolio, la première question que je me suis posée était comment ce site devrait-il me présenter ?
Je pensais qu'il ne suffisait pas de simplement énumérer des listes de projets ou d'attirer l'attention avec une seule interaction. Je voulais créer une expérience fluide allant de la première impression à l'exploration réelle du contenu, au téléchargement de CV, et à l'interaction avec les visiteurs — un parcours complet.
Ainsi, Chaen est un projet full-stack qui intègre dans un même produit un portfolio, un blog, une archive de projets, une page de diffusion de CV, un livre d'or et un éditeur administrateur.

Scène héro 3D — L'interaction comme porte d'entrée
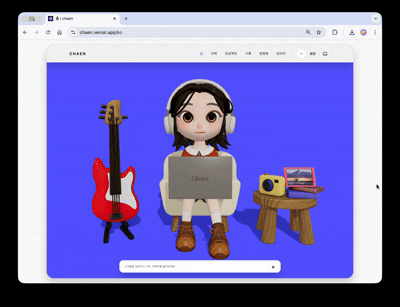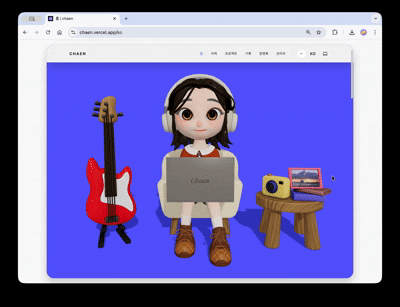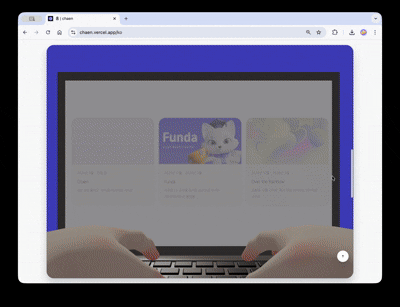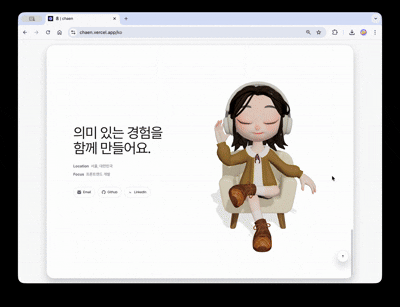
L'objectif de la première page du site portfolio était de faire en sorte que la scène en 3D s'intègre naturellement au contenu web réel.
La scène héro accueille un personnage. À intervalles réguliers, des animations de frappe et de réponse aux notifications sont lancées. En cliquant sur la guitare à gauche de l'écran, des sons différents sont générés par corde et une piste en boucle est jouée. En cliquant sur la caméra à droite, un visualiseur d'images s'ouvre, et l'image choisie devient la texture d'un cadre dans la scène. Chaque interaction est conçue de manière indépendante dans une structure de type trigger-response, permettant à la scène 3D de fonctionner comme une interface interactive et non pas simplement comme un arrière-plan.
En déroulant la page, la caméra fait une rotation de 180 degrés et le point de vue passe à l'écran de l'ordinateur portable du personnage. L'ordinateur portable est progressivement agrandi, remplaçant l'affichage par une superposition HTML réelle qui mène à une vitrine de projets cliquables.
plaintext
Plus que la fluidité de l'exécution, la cohérence des interactions dans le timing de transition était cruciale. Il ne devait pas être possible de cliquer sur l'UI HTML pendant le fondu de la scène 3D. Donc, les pointer-events de la couche Web UI ont été contrôlés avec un seuil d'opacité pour éviter toute interaction incorrecte durant la transition.
Pourquoi choisir R3F
J'ai opté pour React Three Fiber(R3F) au lieu de Three.js pur pour la bibliothèque de rendu 3D.
Ce projet est basé sur Next.js + React. Avec Three.js pur, il faut gérer manuellement chaque réglage comme l'initialisation de la Scène, de la Caméra, du Rendu, la boucle d'animation et la gestion du redimensionnement. R3F abstrait ce boilerplate dans un modèle de composant React, ce qui permet de déclarer les caméras, les lumières et les objets en JSX, et de synchroniser naturellement l'état React externe avec la scène 3D. C'était un choix particulièrement pertinent pour la structure étroitement connectée de progression de défilement, d'état de la couche UI et de scène 3D.
Pipeline des assets 3D — de Blender au web
Lorsque j'ai commencé à implémenter des personnages 3D sur Funda, j'ai directement fait face aux limites de la structure Rigified Bone en temps réel. Mon expérience m'a montré qu'il fallait aborder les problèmes de performance dès l'étape de conception des assets, plutôt qu'au niveau de l'exécution. Sur Funda, nous avons solutionné cela en pré-cuisant les données d'animation dans Blender pour réduire les calculs de matrices des os en temps réel, mais les optimisations au niveau du pipeline de rendu et de géométrie tels que la mémoire texture, les appels de dessin (Draw Call), et le nombre de sommets devaient être traitées indépendamment.
Les assets 3D de Chaen ont été conçus avec cette perspective dès le départ. Le runtime (R3F/Three.js) ne s'occupe que de l'interaction, tandis que les coûts sont réduits au niveau de Blender.
다이어그램을 렌더링하는 중입니다...
Optimisation des sommets — Obtenir une qualité high-poly sans appliquer Subdivision
Problème: La méthode intuitive pour rendre un maillage plus lisse consiste à appliquer le Subdivision Surface. Cependant, chaque application multiplie par quatre le nombre de faces, augmentant ainsi les coûts de rendu dans un environnement web.
Solution: Sans appliquer la Subdivision, nous avons recalculé uniquement la direction des normales avec le modificateur de Normal Pondéré. Bien que le nombre de faces reste le même, les normales utilisées pour les calculs d'éclairage sont interpolées pour apparaître aussi lisses qu'une high-poly. Selon la structure du maillage, il peut y avoir des détours dans les directions de normale à certains bords, mais le réglage manuel du poids des normales par face permet d'assurer la qualité souhaitée sans cassures.
Atlas de Texture — Réduction des appels de dessin
Problème: Trois.js ne peut pas rendre en une seule fois les objets ayant des materials différents. L'utilisation de materials distincts pour chaque partie entraîne autant d'appels de dessin que de parties.
Solution: Les parties liées ont été regroupées en fonction de leur usage, le UV ayant été réarrangé selon les coordonnées de l'atlas, et le tout a été intégré dans une texture d'atlas unique partageant la référence material. Les objets partageant le même material sont unis en un seul appel de dessin.
Packing ORM — 3 textures en 1
Problème: Dans le workflow PBR, Occlusion, Rugosité et Metalness nécessitent chacun une texture distincte. Trois textures signifient trois fois la mémoire GPU et la quantité de transfert réseau.
Solution: Puisque les trois canaux comportent des données en niveaux de gris (valeurs scalaire de 0 à 1), ils ont été regroupés chacun dans le canal R, G, B d'une seule image. En passant de 3 textures à 1, nous réduisons à la fois la mémoire GPU et la charge de transfert de chargement initial.
Instanciation — Élimination des calculs redondants pour les géométries identiques
Quand des géométries identiques sont utilisées à plusieurs endroits, la technique d'instanciation permet de les charger une seule fois dans le GPU, éliminant les calculs redondants.
Mode scène réactif
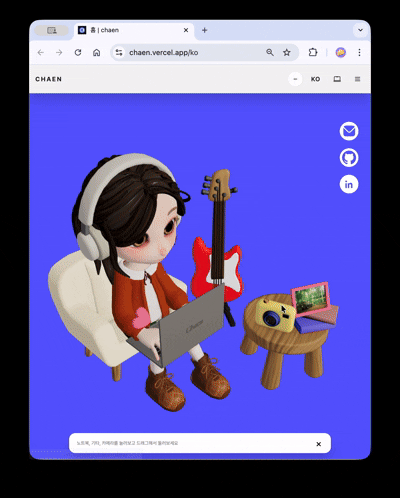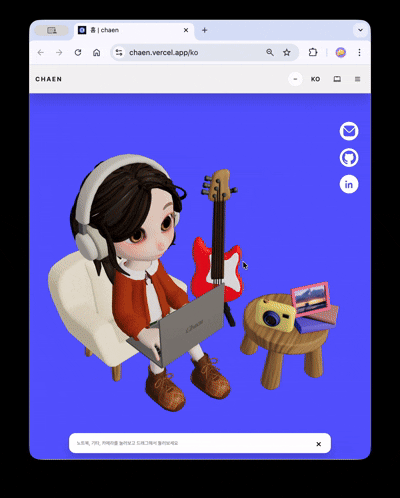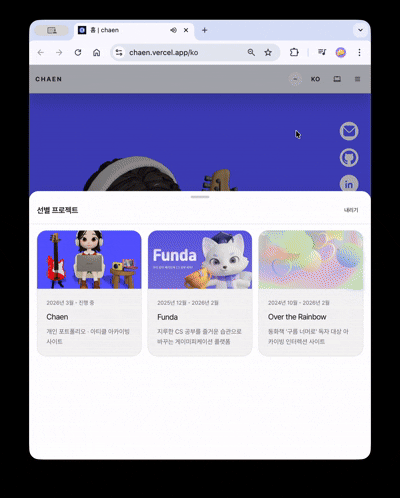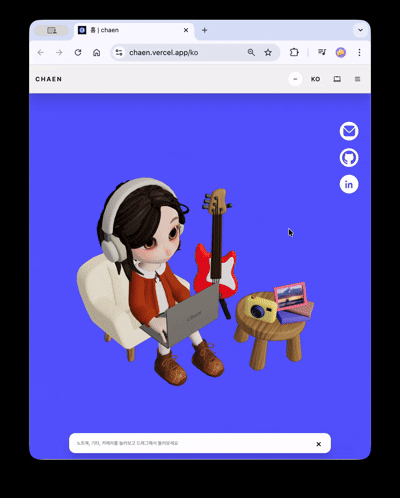
La scène 3D se divise en deux modes basés sur le ratio d'aspect du viewport : stacked (dominance verticale) / wide (dominance horizontale).
- stacked: Interaction centrée sur le tap · glisser. Réduction des coûts de rendu avec un réglage prudent du seuil DPR pour la scène de contact.
- wide: Conservation de l'expérience de transition de caméra basée sur le défilement. Seule la qualité nécessaire est conservée.
La règle a été simplifiée pour qu'il n'y ait qu'une seule bifurcation entre les deux modes, sans état intermédiaire. Pour les utilisateurs de prefers-reduced-motion, les déplacements de caméra brusques sont omis, offrant une expérience d'entrée courte et concise, et pour les environnements non pris en charge par WebGL, une solution de repli sécurisée sans 3D est proposée.
Multilinguisme et SEO — Même dans l'invisible
Chaen prend en charge quatre langues : ko / en / ja / fr. Dans un site multilingue, l'important n'est pas seulement d'avoir de nombreuses chaînes traduites, mais d'avoir une structure qui préserve simultanément l'expérience utilisateur et la visibilité de recherche malgré les omissions de traduction ou les divergences de parcours.
Modèle de données de contenu
Nous avons conçu le contenu selon une structure . Les , , conservent un identifiant basé sur un slug commun, tandis que les titres et les corps réels sont gérés pour chaque locale dans des tables séparées comme . Lorsque la requête est effectuée, nous sélectionnons la traduction la plus appropriée dans l'ordre : locale cible → → → → .
Tout en maintenant la stabilité des références URL et de contenu, seuls les titres, descriptions et étiquettes à afficher à l'écran sont choisis à partir du pool de traductions.
Pipeline de traduction — Automatisation n8n
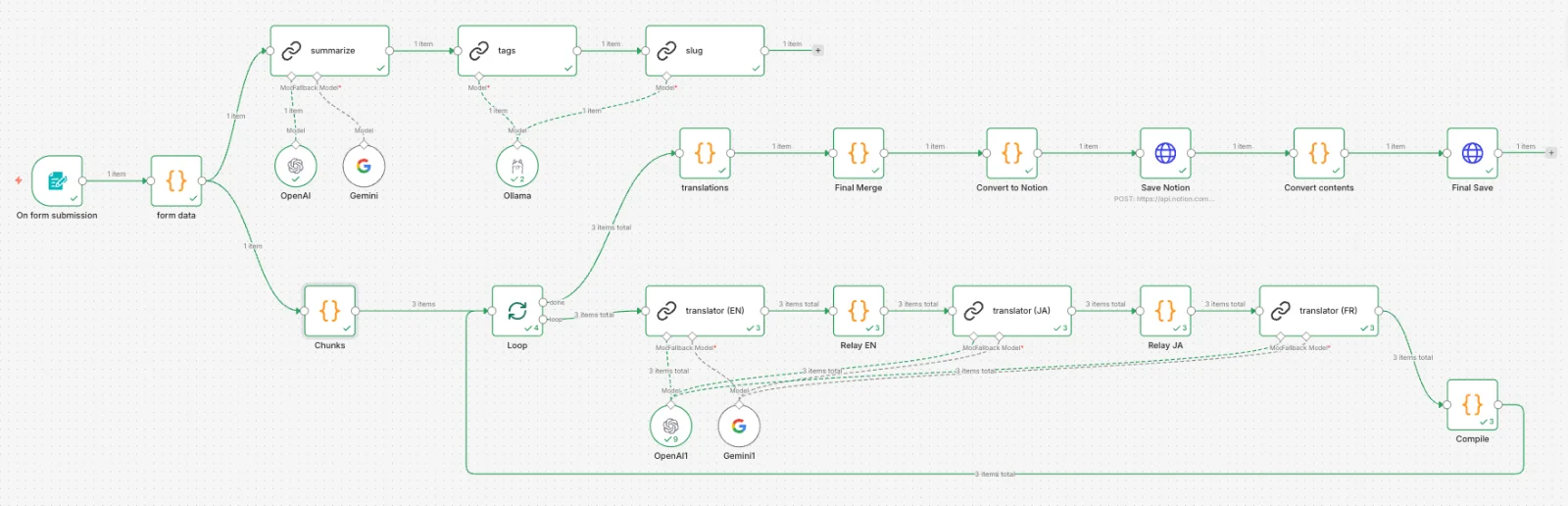
Même si le modèle de données de contenu est séparé en article_translations, si la traduction elle-même devient un goulot d'étranglement, il devient difficile de maintenir le support multilingue. Traduire, réviser et enregistrer un article en trois langues devient fastidieux si cela est fait manuellement à chaque fois que nous publions un texte.
Pour résoudre ce problème, nous avons mis en place un pipeline d'automatisation des traductions basé sur n8n. Lorsqu'un titre, une description et le corps en Markdown sont saisis dans le formulaire, l'extraction des tags, la génération de slug, la traduction en EN/JA/FR et l'enregistrement dans Notion sont effectués d'un seul coup.
plaintext
Quelques choix de conception :
Résumé préalable
- En insérant le corps entier dans le LLM pour tags/slug, le phénomène de redonner simplement le corps à la place d'un résumé se produit. Nous générons d'abord un résumé de 2-3 phrases à partir duquel nous séparons pour référence la génération de tags et de slug.
Séparation des modèles par rôle
Pour les travaux nécessitant une haute qualité comme la traduction et le résumé, nous utilisons OpenAI. Pour les tâches qui nécessitent une sortie structurée courte comme les tags/le slug, nous utilisons Ollama localement. Cela réduit les coûts d'API tout en maintenant la qualité.
Traduction par chunks
Traduire un long article d'un seul coup peut entraîner des omissions de contenu ou des ruptures de la structure Markdown. Nous divisons en chunks selon les titres H2 et traitons de manière séquentielle. Les résultats de la traduction de chaque chunk sont accumulés à un nœud de relais pour être transmis à la langue suivante, et l'ensemble est fusionné après la boucle.
Sortie structurée
Les résultats de traduction sont reçus sous forme de JSON { title, description, content } pour être séparés entre les propriétés (métadonnées) et le corps de la page (blocs) dans Notion. Le corps est divisé en lots pour les requêtes PATCH, respectant la limitation de 100 blocs de l'API Notion.
Actifs locaux invisibles
Nous avons géré comme biens locaux non seulement le texte visible à l'écran, mais aussi les aria-label, les placeholders, les messages d'erreur et le texte d'état pour les lecteurs d'écran. Si seul le corps est traduit et que les messages restent dans une autre langue, l'expérience est vite fragmentée. Nous veillons à ce que la « langue vue » par l'utilisateur et la « langue lue » par le dispositif d'assistance ne soient pas séparées.
Infrastructure SEO
Automatisation canonique · hreflang
À l’étape generateMetadata de chaque page, nous avons configuré le calcul automatique des canonicals spécifiques aux locales et des alternates hreflang. Si une traduction manque, un fallback locale est indiqué comme canonique pour réduire le potentiel de contenu dupliqué tout en continuant à fournir le contenu fallback aux utilisateurs.
Données structurées JSON-LD
Nous avons injecté des schémas BlogPosting pour les détails d'articles, CreativeWork pour les détails de projets et pour le fil d'Ariane commun. Cela permet aux moteurs de recherche de bien interpréter le type de document, le titre, la date de publication et la hiérarchie de la page en plus de l'analyse HTML.
Sitemap/robots dynamiques
Au lieu de fichiers XML statiques, nous générons le sitemap et robots à partir de code basé sur l'API Metadata de Next.js. Cela reflète directement les données de Supabase et la structure réelle de l'URL, et maintient automatiquement le sitemap à jour même si le nombre de locales augmente ou si les données changent. Les chemins d'administrateur, de callback et de livre d'or sont explicitement bloqués avec noindex, nofollow.
Amélioration de la vitesse d’accès à la page de détails — De 5 secondes à moins de 1 seconde
Lors du passage de la liste aux détails d’un article, le temps d’attente ressenti pouvait atteindre environ 5 secondes. La structure où l’utilisateur devait attendre que la liste d’archives à gauche, les labels de tags, les articles associés et le traitement de fallback pour les locales multilingues soient tous prêts avec la même priorité était problématique. Ce n'était pas parce que chaque fetch était lent, mais parce que rien n’apparaissait avant que toutes les couches en série ne soient terminées.
Streaming prioritaire du contenu principal — Séparation du timing de rendu
Les données essentielles pour le shell de contenu principal et les données auxiliaires qui peuvent arriver plus tard ont été séparées. La liste des archives, les tags, et les articles associés sont lancés avec une promesse sans await, puis transmis avec un fallback de suspense au niveau des sections. Le contenu principal est affiché en premier, et les sections auxiliaires sont chargées par étapes via un squelette.
다이어그램을 렌더링하는 중입니다...
Unification de la structure du cache
L’ISR au niveau de la page (revalidate = 3600) et le cache d’entité unstable_cache étaient superposés, ce qui compliquait la détermination des causes d’obsolescence. En supprimant l’ISR de page et en ne gardant que , le suivi des causes d’obsolescence se fait désormais en un seul endroit.
La vérification des occurrences de cache se mesure directement dans les logs du serveur. Le corps de fonction unstable_cache s’exécute uniquement en cas de cache miss, donc en intégrant un log [cache-miss:article], on peut savoir si une requête DB a été lancée.
plaintext
[cache-miss:article] slug="fe-performance" locale="ko" ← n’apparaît qu’en cas de cache miss
[perf:article] slug="fe-performance" locale="ko" ms=4 ← toujours affiché (hit: <5ms)
[perf:article] slug="fe-performance" locale="ko" ms=340 ← coût de requête exposé en cas de missSéparation de la responsabilité du cache pour les commentaires et le contenu
Les commentaires ont des besoins de fraîcheur totalement différents de ceux du contenu. Nous avons isolé les commentaires dans un cache mémoire à durée de vie déterminée pour la session du navigateur (TTL 60 secondes) afin de ne pas bloquer l’accès au contenu. Immédiatement après l’écriture, la modification ou la suppression d’un commentaire, toutes les entrées de cache de l’article concerné sont supprimées pour éviter la réutilisation de données obsolètes.
Amélioration de la structure des requêtes de défilement infini
La fonction « consulter la page suivante » du défilement infini utilisait une Action Serveur basée sur POST. La structure était telle qu’une simple requête de lecture utilisait un transport de mutation. Nous avons changé cela pour GET /api/articles?cursor=... via un gestionnaire de route et ajouté Cache-Control: s-maxage=60, stale-while-revalidate=300. La fraîcheur des données réelles est désormais déterminée par le cache d’entité, et le transport fonctionne comme pour une ressource en lecture.
Résultats
La vitesse perçue a été réduite d’environ 5 secondes à 0,5~1 seconde. Plus encore que les chiffres, c’est la disparition de la « sensation de retard autour » et l’affichage stable et prioritaire du contenu principal qui se font remarquer.
Cette structure a pu être rationalisée par étapes grâce à la répartition des responsabilités route, vue, entité et fonctionnalité selon la perspective FSD. Cela a permis de séparer les couches formant des goulots d'étranglement une par une.
4. Pagination de curseur Offset → Keyset et UX de navigation
À mesure que le contenu augmente, la navigation dans les listes devient un problème de structure de l'information, et non plus uniquement un problème de rendu de liste. La méthode Offset traditionnelle présentait deux problèmes. Premièrement, au fur et à mesure que l'on avançait dans les pages, la base de données devait lire et rejeter toutes les données précédentes, entraînant une dégradation des performances en O(N). Deuxièmement, lorsque de nouveaux articles étaient publiés pendant le défilement, le flux sautait avec une exposition en double.
Conception de la structure du curseur
Nous avons implémenté une pagination basée sur des coordonnées absolues en sérialisant la combinaison publish_at + id en curseurs opaques. Comme elle interroge en fonction d'un critère fixe « avant un certain point dans le temps », le flux ne se brise pas lorsque les articles sont mis à jour en temps réel, et l'on ne consulte que les données nécessaires le long de l'index, maintenant ainsi les performances à O(log N) indépendamment de la quantité de données.
다이어그램을 렌더링하는 중입니다...
Extension Keyset pour les recherches — PostgreSQL FTS + curseur par rang
Nous avons étendu la même structure de curseur aux résultats de recherche. Lorsqu'une requête est présente, les coordonnées de tri à trois niveaux de pertinence (rang) + publish_at + id sont sérialisées en curseur pour maintenir l'ordre de pertinence sans doublon ou omission aux limites de page.
Les performances de recherche ont été optimisées pour utiliser un index GIN, en calculant préalablement les colonnes tsvector avec un déclencheur de base de données. Au lieu d'utiliser le CPU à chaque demande de recherche, nous créons une empreinte à la génération ou modification des données. Nous avons également amélioré la précision de la recherche en attribuant des scores différenciés au titre (poids A) et à la description (poids B).
다이어그램을 렌더링하는 중입니다...
Connexion entre UX de navigation et SEO
Les URL basées sur les curseurs incluent l'état, ce qui peut influencer négativement l'indexation des recherches. Nous avons appliqué noindex, follow et la balise Canonical aux URL de curseur pour éviter les doubles indexations par les robots, tout en générant les métadonnées rel="prev" / pour maintenir la structure de suivi des liens statiques.
Gestion des liens profonds anormaux
Keyset ne peut pas restaurer la position cible uniquement avec un numéro de page. Les liens profonds manuels au format ?page=N sont traités par notFound() lorsqu'ils sont accédés sans curseur, éliminant ainsi le coût de restauration en série des pages intermédiaires par le serveur.
Ajustement des archives détaillées
L'archive sur la gauche des pages détaillées intègre les éléments consultés pour aider l'utilisateur à conserver le contexte de la liste. Le nextCursor est recalculé à partir de l'élément de rendu final pour assurer une continuité sans omission avec la page suivante.
Porte de chargement automatique
Pour éviter les demandes supplémentaires involontaires lorsque le sentinelle apparaît initialement dans le viewport, le chargement automatique est activé uniquement après que l'utilisateur a montré une intention de défilement réelle.
다이어그램을 렌더링하는 중입니다...
5. Accessibilité et qualité de l'interaction
Plus un site a d'interactions, plus la qualité de l'accessibilité peut s'effondrer à cause de petites erreurs accumulées. L'accessibilité a été traitée non pas comme une simple vérification de fin de projet, mais comme une norme de qualité à respecter tout au long de la conception des interactions.
Piège à focus pour les modales et popovers
J’ai créé un hook commun qui gère le déplacement vers le premier élément de focus à l'entrée, la circulation par « Tab », la fermeture par « Échap », et le retour au focus précédent à la fermeture. Tous les composants sont regroupés dans une couche commune, ce qui permet de maintenir un flux de focus cohérent même en cas d'augmentation des interactions.
Transmission d'état
Le formulaire de recherche applique des états tels que , , pour transmettre les états de progression invisibles visuellement. Pour les spoilers, les filtres de tags, la pagination, et les menus d'action, j’ai appliqué de manière cohérente , , et le style focus-visible.
Icônes et actifs localisés
J’ai créé un wrapper commun pour les icônes qui distingue l'utilisation décorative ou informative à l'aide de et de . Les textes pour les lecteurs d'écran connectés à , , et , ainsi que les indices de raccourcis clavier et les messages de validation des entrées sont gérés par localité. Cela permet de s'assurer que la « langue vue » par l'utilisateur et la « langue lue » par les appareils d'assistance ne sont pas dissociées.
Conclusion
Chaen est plus qu'un simple portfolio personnel. C'est un projet qui montre comment je conçois des produits frontend selon certains critères.
Bien que j'aime les interactions, je ne veux pas expliquer un projet uniquement en termes d'interaction. Une bonne interaction devient une expérience produit lorsqu'elle est conçue en tenant compte des performances, de l'accessibilité, de la structure de l'information, de l'optimisation pour la recherche, et de l'opérationnalité. Chaen est le travail qui incarne le plus intensément ce point de vue.